示例 2:
--输入:matrix = [] -输出:0 -- -
示例 3:
-输入:matrix = [["0"]] 输出:0-
示例 4:
+示例 3:
输入:matrix = [["1"]] 输出:1-
示例 5:
- --输入:matrix = [["0","0"]] -输出:0 --
提示:
diff --git a/solution/0600-0699/0616.Add Bold Tag in String/README.md b/solution/0600-0699/0616.Add Bold Tag in String/README.md index 453e0532bffd0..bae0776facdf7 100644 --- a/solution/0600-0699/0616.Add Bold Tag in String/README.md +++ b/solution/0600-0699/0616.Add Bold Tag in String/README.md @@ -6,19 +6,26 @@ -给你一个字符串 s 和一个字符串列表 words ,你需要将在字符串列表中出现过的 s 的子串添加加粗闭合标签 <b> 和 </b> 。
给定字符串 s 和字符串数组 words。
如果两个子串有重叠部分,你需要把它们一起用一对闭合标签包围起来。同理,如果两个子字符串连续被加粗,那么你也需要把它们合起来用一对加粗标签包围。
+对于 s 内部的子字符串,若其存在于 words 数组中, 则通过添加闭合的粗体标签 <b> 和 </b> 进行加粗标记。
返回添加加粗标签后的字符串 s 。
+
示例 1:
输入: s = "abcxyz123", words = ["abc","123"] 输出:"<b>abc</b>xyz<b>123</b>" +解释:两个单词字符串是 s 的子字符串,如下所示: "abcxyz123"。 +我们在每个子字符串之前添加<b>,在每个子字符串之后添加</b>。
示例 2:
@@ -26,25 +33,31 @@输入:s = "aaabbcc", words = ["aaa","aab","bc"] 输出:"<b>aaabbc</b>c" +解释: +"aa"作为子字符串出现了两次: "aaabbb" 和 "aaabbb"。 +"b"作为子字符串出现了三次: "aaabbb"、"aaabbb" 和 "aaabbb"。 +我们在每个子字符串之前添加<b>,在每个子字符串之后添加</b>: "<b>a<b>a</b>a</b><b>b</b><b>b</b><b>b</b>"。 +由于前两个<b>重叠,把它们合并得到: "<b>aaa</b><b>b</b><b>b</b><b>b</b>"。 +由于现在这四个<b>是连续的,把它们合并得到: "<b>aaabbb</b>"。-
+
提示:
1 <= s.length <= 10000 <= words.length <= 1001 <= words[i].length <= 10001 <= s.length <= 10000 <= words.length <= 1001 <= words[i].length <= 1000s 和 words[i] 由英文字母和数字组成words 中的所有值 互不相同+
注:此题与「758 - 字符串中的加粗单词」相同 - https://leetcode.cn/problems/bold-words-in-string
-+
## 解法 diff --git a/solution/0600-0699/0616.Add Bold Tag in String/README_EN.md b/solution/0600-0699/0616.Add Bold Tag in String/README_EN.md index 3914e01399956..b74499f357ef1 100644 --- a/solution/0600-0699/0616.Add Bold Tag in String/README_EN.md +++ b/solution/0600-0699/0616.Add Bold Tag in String/README_EN.md @@ -35,7 +35,7 @@ We add <b> before each substring and </b> after each substring. "b" appears as a substring three times: "aaabbb", "aaabbb", and "aaabbb". We add <b> before each substring and </b> after each substring: "<b>a<b>a</b>a</b><b>b</b><b>b</b><b>b</b>". Since the first two <b>'s overlap, we merge them: "<b>aaa</b><b>b</b><b>b</b><b>b</b>". -Since now the four <b>'s are consecuutive, we merge them: "<b>aaabbb</b>". +Since now the four <b>'s are consecutive, we merge them: "<b>aaabbb</b>".
diff --git a/solution/0800-0899/0828.Count Unique Characters of All Substrings of a Given String/README.md b/solution/0800-0899/0828.Count Unique Characters of All Substrings of a Given String/README.md index b88fd847b8230..2a17c2cfad008 100644 --- a/solution/0800-0899/0828.Count Unique Characters of All Substrings of a Given String/README.md +++ b/solution/0800-0899/0828.Count Unique Characters of All Substrings of a Given String/README.md @@ -31,7 +31,7 @@
输入: s = "ABA"
输出: 8
-解释: 除了 countUniqueChars("ABA") = 1 之外,其余与示例 1 相同。
+解释: 除了 countUniqueChars("ABA") = 1 之外,其余与示例 1 相同。
示例 3:
diff --git a/solution/1900-1999/1921.Eliminate Maximum Number of Monsters/README.md b/solution/1900-1999/1921.Eliminate Maximum Number of Monsters/README.md index 3c52de7cb6d3e..1d3e664ebfaf1 100644 --- a/solution/1900-1999/1921.Eliminate Maximum Number of Monsters/README.md +++ b/solution/1900-1999/1921.Eliminate Maximum Number of Monsters/README.md @@ -6,17 +6,17 @@ -你正在玩一款电子游戏,在游戏中你需要保护城市免受怪物侵袭。给你一个 下标从 0 开始 且长度为 n 的整数数组 dist ,其中 dist[i] 是第 i 个怪物与城市的 初始距离(单位:米)。
你正在玩一款电子游戏,在游戏中你需要保护城市免受怪物侵袭。给定一个 下标从 0 开始 且大小为 n 的整数数组 dist ,其中 dist[i] 是第 i 个怪物与城市的 初始距离(单位:米)。
怪物以 恒定 的速度走向城市。给你一个长度为 n 的整数数组 speed 表示每个怪物的速度,其中 speed[i] 是第 i 个怪物的速度(单位:米/分)。
怪物以 恒定 的速度走向城市。每个怪物的速度都以一个长度为 n 的整数数组 speed 表示,其中 speed[i] 是第 i 个怪物的速度(单位:千米/分)。
怪物从 第 0 分钟 时开始移动。你有一把武器,并可以 选择 在每一分钟的开始时使用,包括第 0 分钟。但是你无法在一分钟的中间使用武器。这种武器威力惊人,一次可以消灭任一还活着的怪物。
+你有一种武器,一旦充满电,就可以消灭 一个 怪物。但是,武器需要 一分钟 才能充电。武器在游戏开始时是充满电的状态,怪物从 第 0 分钟 时开始移动。
-一旦任一怪物到达城市,你就输掉了这场游戏。如果某个怪物 恰 在某一分钟开始时到达城市,这会被视为 输掉 游戏,在你可以使用武器之前,游戏就会结束。
+一旦任一怪物到达城市,你就输掉了这场游戏。如果某个怪物 恰好 在某一分钟开始时到达城市(距离表示为0),这也会被视为 输掉 游戏,在你可以使用武器之前,游戏就会结束。
-返回在你输掉游戏前可以消灭的怪物的 最大 数量。如果你可以在所有怪物到达城市前将它们全部消灭,返回 n 。
返回在你输掉游戏前可以消灭的怪物的 最大 数量。如果你可以在所有怪物到达城市前将它们全部消灭,返回 n 。
+
示例 1:
@@ -25,9 +25,8 @@ 输出:3 解释: 第 0 分钟开始时,怪物的距离是 [1,3,4],你消灭了第一个怪物。 -第 1 分钟开始时,怪物的距离是 [X,2,3],你没有消灭任何怪物。 -第 2 分钟开始时,怪物的距离是 [X,1,2],你消灭了第二个怪物。 -第 3 分钟开始时,怪物的距离是 [X,X,1],你消灭了第三个怪物。 +第 1 分钟开始时,怪物的距离是 [X,2,3],你消灭了第二个怪物。 +第 3 分钟开始时,怪物的距离是 [X,X,2],你消灭了第三个怪物。 所有 3 个怪物都可以被消灭。示例 2:
@@ -37,7 +36,7 @@ 输出:1 解释: 第 0 分钟开始时,怪物的距离是 [1,1,2,3],你消灭了第一个怪物。 -第 1 分钟开始时,怪物的距离是 [X,0,1,2],你输掉了游戏。 +第 1 分钟开始时,怪物的距离是 [X,0,1,2],所以你输掉了游戏。 你只能消灭 1 个怪物。 @@ -52,14 +51,14 @@ 你只能消灭 1 个怪物。 -+
提示:
n == dist.length == speed.length1 <= n <= 1051 <= dist[i], speed[i] <= 1051 <= n <= 1051 <= dist[i], speed[i] <= 105SmallestInfiniteSet() 初始化 SmallestInfiniteSet 对象以包含 所有 正整数。int popSmallest() 移除 并返回该无限集中的最小整数。void addBack(int num) 如果正整数 num 不 存在于无限集中,则将一个 num 添加 到该无限集中。void addBack(int num) 如果正整数 num 不 存在于无限集中,则将一个 num 添加 到该无限集最后。
示例:
-输入 ++输入 ["SmallestInfiniteSet", "addBack", "popSmallest", "popSmallest", "popSmallest", "addBack", "popSmallest", "popSmallest", "popSmallest"] [[], [2], [], [], [], [1], [], [], []] 输出 diff --git a/solution/2300-2399/2397.Maximum Rows Covered by Columns/README.md b/solution/2300-2399/2397.Maximum Rows Covered by Columns/README.md index e60ed0cf34ed8..dbdb1cfae87fa 100644 --- a/solution/2300-2399/2397.Maximum Rows Covered by Columns/README.md +++ b/solution/2300-2399/2397.Maximum Rows Covered by Columns/README.md @@ -6,33 +6,49 @@ -给你一个下标从 0 开始的
+m x n二进制矩阵mat和一个整数cols,表示你需要选出的列数。给你一个下标从 0 开始、大小为
-m x n的二进制矩阵matrix;另给你一个整数numSelect,表示你必须从matrix中选择的 不同 列的数量。如果一行中,所有的
+1都被你选中的列所覆盖,那么我们称这一行 被覆盖 了。如果一行中所有的
-1都被你选中的列所覆盖,则认为这一行被 覆盖 了。请你返回在选择
+cols列的情况下,被覆盖 的行数 最大 为多少。形式上,假设
+ +s = {c1, c2, ...., cnumSelect}是你选择的列的集合。对于矩阵中的某一行row,如果满足下述条件,则认为这一行被集合s覆盖:
matrix[row][col] == 1 的每个单元格 matrix[row][col](0 <= col <= n - 1),col 均存在于 s 中,或者row 中 不存在 值为 1 的单元格。你需要从矩阵中选出 numSelect 个列,使集合覆盖的行数最大化。
返回一个整数,表示可以由 numSelect 列构成的集合 覆盖 的 最大行数 。
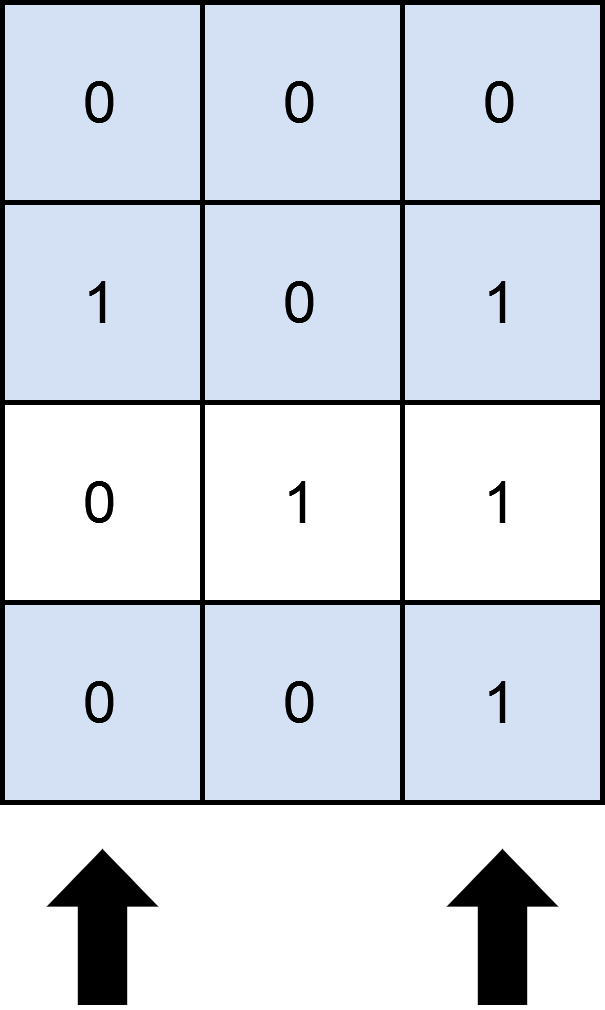
示例 1:
-
输入:mat = [[0,0,0],[1,0,1],[0,1,1],[0,0,1]], cols = 2 ++输入:matrix = [[0,0,0],[1,0,1],[0,1,1],[0,0,1]], numSelect = 2 输出:3 解释: -如上图所示,覆盖 3 行的一种可行办法是选择第 0 和第 2 列。 -可以看出,不存在大于 3 行被覆盖的方案,所以我们返回 3 。 -+图示中显示了一种覆盖 3 行的可行办法。 +选择 s = {0, 2} 。 +- 第 0 行被覆盖,因为其中没有出现 1 。 +- 第 1 行被覆盖,因为值为 1 的两列(即 0 和 2)均存在于 s 中。 +- 第 2 行未被覆盖,因为 matrix[2][1] == 1 但是 1 未存在于 s 中。 +- 第 3 行被覆盖,因为 matrix[2][2] == 1 且 2 存在于 s 中。 +因此,可以覆盖 3 行。 +另外 s = {1, 2} 也可以覆盖 3 行,但可以证明无法覆盖更多行。
示例 2:
-
输入:mat = [[1],[0]], cols = 1 ++输入:matrix = [[1],[0]], numSelect = 1 输出:2 解释: -选择唯一的一列,两行都被覆盖了,原因是整个矩阵都被覆盖了。 +选择唯一的一列,两行都被覆盖了,因为整个矩阵都被覆盖了。 所以我们返回 2 。@@ -41,11 +57,11 @@提示:
m == mat.lengthn == mat[i].lengthm == matrix.lengthn == matrix[i].length1 <= m, n <= 12mat[i][j] 要么是 0 要么是 1 。1 <= cols <= nmatrix[i][j] 要么是 0 要么是 11 <= numSelect <= n政府批准了可以额外建造 k 座供电站,你需要决定这些供电站分别应该建在哪里,这些供电站与已经存在的供电站有相同的供电范围。
给你两个整数 r 和 k ,如果以最优策略建造额外的发电站,返回所有城市中,最小供电站数目的最大值是多少。
给你两个整数 r 和 k ,如果以最优策略建造额外的发电站,返回所有城市中,最小电量的最大值是多少。
这 k 座供电站可以建在多个城市。
编写一条 SQL 查询,找出 Meta/Facebook 平台上每个用户的受欢迎度的百分比。受欢迎度百分比定义为用户拥有的朋友总数除以平台上的总用户数,然后乘以 100,并 四舍五入保留 2 位小数 。
返回按照 user1 升序 排序的结果表。
查询结果的格式如下所示。
+查询结果格式如下示例所示。
diff --git a/solution/2700-2799/2720.Popularity Percentage/README_EN.md b/solution/2700-2799/2720.Popularity Percentage/README_EN.md index 6899d5d412d79..52a0fe5e903b9 100644 --- a/solution/2700-2799/2720.Popularity Percentage/README_EN.md +++ b/solution/2700-2799/2720.Popularity Percentage/README_EN.md @@ -13,15 +13,15 @@ | user1 | int | | user2 | int | +-------------+------+ -(user1, user2) is the primary key of this table. +(user1, user2) is the primary key (combination of unique values) of this table. Each row contains information about friendship where user1 and user2 are friends. -
Write an SQL query to find the popularity percentage for each user on Meta/Facebook. The popularity percentage is defined as the total number of friends the user has divided by the total number of users on the platform, then converted into a percentage by multiplying by 100, rounded to 2 decimal places.
+Write a solution to find the popularity percentage for each user on Meta/Facebook. The popularity percentage is defined as the total number of friends the user has divided by the total number of users on the platform, then converted into a percentage by multiplying by 100, rounded to 2 decimal places.
Return the result table ordered by user1 in ascending order.
The query result format is in the following example.
+The result format is in the following example.
Example 1:
diff --git a/solution/2900-2999/2922.Market Analysis III/README.md b/solution/2900-2999/2922.Market Analysis III/README.md index 4ea7e1d6cc868..7b7f4f1f1ee2d 100644 --- a/solution/2900-2999/2922.Market Analysis III/README.md +++ b/solution/2900-2999/2922.Market Analysis III/README.md @@ -16,7 +16,7 @@ | join_date | date | | favorite_brand | varchar | +----------------+---------+ -seller_id 是该表的主键。 +seller_id 是该表具有唯一值的列。 该表包含卖家的 ID, 加入日期以及最喜欢的品牌。 @@ -29,7 +29,7 @@ seller_id 是该表的主键。 | item_id | int | | item_brand | varchar | +---------------+---------+ -item_id 是该表的主键。 +item_id 是该表具有唯一值的列。 该表包含商品 ID 和商品品牌。表: Orders
Table: Orders
输入:nums = [3,3,3,3,3] 输出:1 -解释:这里只有一个块,即整个数组(因为所有数字都相等),即:[3,3,3,3,3]。因此答案是 1。 +解释:这里只有一个块,也就是整个数组(因为所有数字都相等),即:[3,3,3,3,3]。因此答案是 1。
示例 2:
diff --git a/solution/2900-2999/2941.Maximum GCD-Sum of a Subarray/README.md b/solution/2900-2999/2941.Maximum GCD-Sum of a Subarray/README.md index 4eff39f912f87..50f250a874044 100644 --- a/solution/2900-2999/2941.Maximum GCD-Sum of a Subarray/README.md +++ b/solution/2900-2999/2941.Maximum GCD-Sum of a Subarray/README.md @@ -1,4 +1,4 @@ -# [2941. Maximum GCD-Sum of a Subarray](https://leetcode.cn/problems/maximum-gcd-sum-of-a-subarray) +# [2941. 子数组的最大 GCD-Sum](https://leetcode.cn/problems/maximum-gcd-sum-of-a-subarray) [English Version](/solution/2900-2999/2941.Maximum%20GCD-Sum%20of%20a%20Subarray/README_EN.md) @@ -6,37 +6,39 @@ -You are given an array of integers nums and an integer k.
给定一个整数数组 nums 和一个整数 k.
The gcd-sum of an array a is calculated as follows:
数组 a 的 gcd-sum 计算方法如下:
s be the sum of all the elements of a.g be the greatest common divisor of all the elements of a.a is equal to s * g.s 为 a 的所有元素的和。g 为 a 的所有元素的 最大公约数。a 的 gcd-sum 等于 s * g.Return the maximum gcd-sum of a subarray of nums with at least k elements.
返回 nums 的至少包含 k 个元素的子数组的 最大 gcd-sum。
-
Example 1:
+ +示例 1:
-Input: nums = [2,1,4,4,4,2], k = 2 -Output: 48 -Explanation: We take the subarray [4,4,4], the gcd-sum of this array is 4 * (4 + 4 + 4) = 48. -It can be shown that we can not select any other subarray with a gcd-sum greater than 48.+输入:nums = [2,1,4,4,4,2], k = 2 +输出:48 +解释:我们选择子数组 [4,4,4],该数组的 gcd-sum 为 4 * (4 + 4 + 4) = 48。 +可以证明我们无法选择任何其他 gcd-sum 大于 48 的子数组。 -
Example 2:
+示例 2:
-Input: nums = [7,3,9,4], k = 1 -Output: 81 -Explanation: We take the subarray [9], the gcd-sum of this array is 9 * 9 = 81. -It can be shown that we can not select any other subarray with a gcd-sum greater than 81.+输入:nums = [7,3,9,4], k = 1 +输出:81 +解释:我们选择子数组 [9],该数组的 gcd-sum 为 9 * 9 = 81。 +可以证明我们无法选择任何其他 gcd-sum 大于 81 的子数组。
-
Constraints:
+ +提示:
n == nums.length给你一个大小为 m x n 的整数矩阵 mat 和一个整数 k 。请你将矩阵中的 奇数 行循环 右 移 k 次,偶数 行循环 左 移 k 次。
给你一个下标从 0 开始且大小为 m x n 的整数矩阵 mat 和一个整数 k 。请你将矩阵中的 奇数 行循环 右 移 k 次,偶数 行循环 左 移 k 次。
如果初始矩阵和最终矩阵完全相同,则返回 true ,否则返回 false 。
Each character of the English alphabet has been mapped to a digit as shown below.
-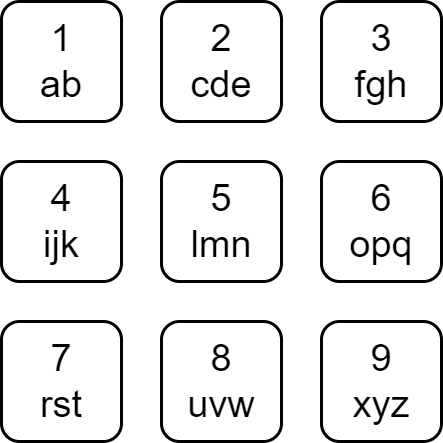
A string is divisible if the sum of the mapped values of its characters is divisible by its length.
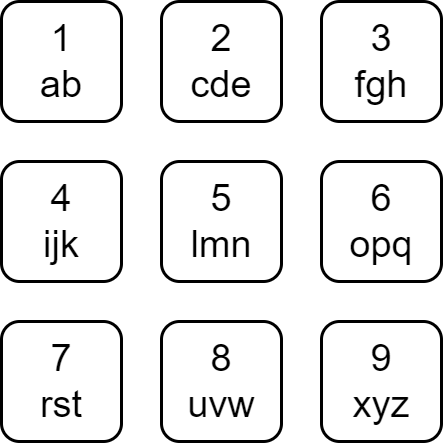
diff --git a/solution/2900-2999/2950.Number of Divisible Substrings/README_EN.md b/solution/2900-2999/2950.Number of Divisible Substrings/README_EN.md index f7cd86b0adea8..df21709af9861 100644 --- a/solution/2900-2999/2950.Number of Divisible Substrings/README_EN.md +++ b/solution/2900-2999/2950.Number of Divisible Substrings/README_EN.md @@ -6,7 +6,7 @@Each character of the English alphabet has been mapped to a digit as shown below.
-
A string is divisible if the sum of the mapped values of its characters is divisible by its length.
diff --git a/solution/2900-2999/2950.Number of Divisible Substrings/images/old_phone_digits.png b/solution/2900-2999/2950.Number of Divisible Substrings/images/old_phone_digits.png new file mode 100644 index 0000000000000..e13d884c43bb7 Binary files /dev/null and b/solution/2900-2999/2950.Number of Divisible Substrings/images/old_phone_digits.png differ diff --git a/solution/CONTEST_README.md b/solution/CONTEST_README.md index 0f7580098c20c..5ef83c9cbc45b 100644 --- a/solution/CONTEST_README.md +++ b/solution/CONTEST_README.md @@ -517,7 +517,7 @@ - [2525. 根据规则将箱子分类](/solution/2500-2599/2525.Categorize%20Box%20According%20to%20Criteria/README.md) - [2526. 找到数据流中的连续整数](/solution/2500-2599/2526.Find%20Consecutive%20Integers%20from%20a%20Data%20Stream/README.md) - [2527. 查询数组 Xor 美丽值](/solution/2500-2599/2527.Find%20Xor-Beauty%20of%20Array/README.md) -- [2528. 最大化城市的最小供电站数目](/solution/2500-2599/2528.Maximize%20the%20Minimum%20Powered%20City/README.md) +- [2528. 最大化城市的最小电量](/solution/2500-2599/2528.Maximize%20the%20Minimum%20Powered%20City/README.md) #### 第 326 场周赛(2023-01-01 10:30, 90 分钟) 参赛人数 3873 diff --git a/solution/README.md b/solution/README.md index 4cc02a9a4f2cf..86bfb1c2fb9b7 100644 --- a/solution/README.md +++ b/solution/README.md @@ -2538,7 +2538,7 @@ | 2525 | [根据规则将箱子分类](/solution/2500-2599/2525.Categorize%20Box%20According%20to%20Criteria/README.md) | `数学` | 简单 | 第 95 场双周赛 | | 2526 | [找到数据流中的连续整数](/solution/2500-2599/2526.Find%20Consecutive%20Integers%20from%20a%20Data%20Stream/README.md) | `设计`,`队列`,`哈希表`,`计数`,`数据流` | 中等 | 第 95 场双周赛 | | 2527 | [查询数组 Xor 美丽值](/solution/2500-2599/2527.Find%20Xor-Beauty%20of%20Array/README.md) | `位运算`,`数组`,`数学` | 中等 | 第 95 场双周赛 | -| 2528 | [最大化城市的最小供电站数目](/solution/2500-2599/2528.Maximize%20the%20Minimum%20Powered%20City/README.md) | `贪心`,`队列`,`数组`,`二分查找`,`前缀和`,`滑动窗口` | 困难 | 第 95 场双周赛 | +| 2528 | [最大化城市的最小电量](/solution/2500-2599/2528.Maximize%20the%20Minimum%20Powered%20City/README.md) | `贪心`,`队列`,`数组`,`二分查找`,`前缀和`,`滑动窗口` | 困难 | 第 95 场双周赛 | | 2529 | [正整数和负整数的最大计数](/solution/2500-2599/2529.Maximum%20Count%20of%20Positive%20Integer%20and%20Negative%20Integer/README.md) | `数组`,`二分查找`,`计数` | 简单 | 第 327 场周赛 | | 2530 | [执行 K 次操作后的最大分数](/solution/2500-2599/2530.Maximal%20Score%20After%20Applying%20K%20Operations/README.md) | `贪心`,`数组`,`堆(优先队列)` | 中等 | 第 327 场周赛 | | 2531 | [使字符串总不同字符的数目相等](/solution/2500-2599/2531.Make%20Number%20of%20Distinct%20Characters%20Equal/README.md) | `哈希表`,`字符串`,`计数` | 中等 | 第 327 场周赛 | @@ -2951,16 +2951,16 @@ | 2938 | [区分黑球与白球](/solution/2900-2999/2938.Separate%20Black%20and%20White%20Balls/README.md) | `贪心`,`双指针`,`字符串` | 中等 | 第 372 场周赛 | | 2939 | [最大异或乘积](/solution/2900-2999/2939.Maximum%20Xor%20Product/README.md) | `贪心`,`位运算`,`数学` | 中等 | 第 372 场周赛 | | 2940 | [找到 Alice 和 Bob 可以相遇的建筑](/solution/2900-2999/2940.Find%20Building%20Where%20Alice%20and%20Bob%20Can%20Meet/README.md) | `栈`,`树状数组`,`线段树`,`数组`,`二分查找`,`单调栈`,`堆(优先队列)` | 困难 | 第 372 场周赛 | -| 2941 | [Maximum GCD-Sum of a Subarray](/solution/2900-2999/2941.Maximum%20GCD-Sum%20of%20a%20Subarray/README.md) | | 困难 | 🔒 | -| 2942 | [查找包含给定字符的单词](/solution/2900-2999/2942.Find%20Words%20Containing%20Character/README.md) | | 简单 | 第 118 场双周赛 | -| 2943 | [最大化网格图中正方形空洞的面积](/solution/2900-2999/2943.Maximize%20Area%20of%20Square%20Hole%20in%20Grid/README.md) | | 中等 | 第 118 场双周赛 | -| 2944 | [购买水果需要的最少金币数](/solution/2900-2999/2944.Minimum%20Number%20of%20Coins%20for%20Fruits/README.md) | | 中等 | 第 118 场双周赛 | -| 2945 | [找到最大非递减数组的长度](/solution/2900-2999/2945.Find%20Maximum%20Non-decreasing%20Array%20Length/README.md) | | 困难 | 第 118 场双周赛 | -| 2946 | [循环移位后的矩阵相似检查](/solution/2900-2999/2946.Matrix%20Similarity%20After%20Cyclic%20Shifts/README.md) | | 简单 | 第 373 场周赛 | -| 2947 | [统计美丽子字符串 I](/solution/2900-2999/2947.Count%20Beautiful%20Substrings%20I/README.md) | | 中等 | 第 373 场周赛 | -| 2948 | [交换得到字典序最小的数组](/solution/2900-2999/2948.Make%20Lexicographically%20Smallest%20Array%20by%20Swapping%20Elements/README.md) | | 中等 | 第 373 场周赛 | -| 2949 | [统计美丽子字符串 II](/solution/2900-2999/2949.Count%20Beautiful%20Substrings%20II/README.md) | | 困难 | 第 373 场周赛 | -| 2950 | [Number of Divisible Substrings](/solution/2900-2999/2950.Number%20of%20Divisible%20Substrings/README.md) | | 中等 | 🔒 | +| 2941 | [子数组的最大 GCD-Sum](/solution/2900-2999/2941.Maximum%20GCD-Sum%20of%20a%20Subarray/README.md) | `数组`,`数学`,`二分查找`,`数论` | 困难 | 🔒 | +| 2942 | [查找包含给定字符的单词](/solution/2900-2999/2942.Find%20Words%20Containing%20Character/README.md) | `数组`,`字符串` | 简单 | 第 118 场双周赛 | +| 2943 | [最大化网格图中正方形空洞的面积](/solution/2900-2999/2943.Maximize%20Area%20of%20Square%20Hole%20in%20Grid/README.md) | `数组`,`排序` | 中等 | 第 118 场双周赛 | +| 2944 | [购买水果需要的最少金币数](/solution/2900-2999/2944.Minimum%20Number%20of%20Coins%20for%20Fruits/README.md) | `队列`,`数组`,`动态规划`,`单调队列` | 中等 | 第 118 场双周赛 | +| 2945 | [找到最大非递减数组的长度](/solution/2900-2999/2945.Find%20Maximum%20Non-decreasing%20Array%20Length/README.md) | `栈`,`队列`,`数组`,`二分查找`,`动态规划`,`单调队列`,`单调栈` | 困难 | 第 118 场双周赛 | +| 2946 | [循环移位后的矩阵相似检查](/solution/2900-2999/2946.Matrix%20Similarity%20After%20Cyclic%20Shifts/README.md) | `数组`,`数学`,`矩阵`,`模拟` | 简单 | 第 373 场周赛 | +| 2947 | [统计美丽子字符串 I](/solution/2900-2999/2947.Count%20Beautiful%20Substrings%20I/README.md) | `字符串`,`枚举`,`前缀和` | 中等 | 第 373 场周赛 | +| 2948 | [交换得到字典序最小的数组](/solution/2900-2999/2948.Make%20Lexicographically%20Smallest%20Array%20by%20Swapping%20Elements/README.md) | `并查集`,`数组`,`排序` | 中等 | 第 373 场周赛 | +| 2949 | [统计美丽子字符串 II](/solution/2900-2999/2949.Count%20Beautiful%20Substrings%20II/README.md) | `哈希表`,`数学`,`字符串`,`数论`,`前缀和` | 困难 | 第 373 场周赛 | +| 2950 | [可整除子串的数量](/solution/2900-2999/2950.Number%20of%20Divisible%20Substrings/README.md) | | 中等 | 🔒 | ## 版权 diff --git a/solution/README_EN.md b/solution/README_EN.md index 17dfdb599c239..4c7974dfa8780 100644 --- a/solution/README_EN.md +++ b/solution/README_EN.md @@ -2949,15 +2949,15 @@ Press Control + F(or Command + F on | 2938 | [Separate Black and White Balls](/solution/2900-2999/2938.Separate%20Black%20and%20White%20Balls/README_EN.md) | `Greedy`,`Two Pointers`,`String` | Medium | Weekly Contest 372 | | 2939 | [Maximum Xor Product](/solution/2900-2999/2939.Maximum%20Xor%20Product/README_EN.md) | `Greedy`,`Bit Manipulation`,`Math` | Medium | Weekly Contest 372 | | 2940 | [Find Building Where Alice and Bob Can Meet](/solution/2900-2999/2940.Find%20Building%20Where%20Alice%20and%20Bob%20Can%20Meet/README_EN.md) | `Stack`,`Binary Indexed Tree`,`Segment Tree`,`Array`,`Binary Search`,`Monotonic Stack`,`Heap (Priority Queue)` | Hard | Weekly Contest 372 | -| 2941 | [Maximum GCD-Sum of a Subarray](/solution/2900-2999/2941.Maximum%20GCD-Sum%20of%20a%20Subarray/README_EN.md) | | Hard | 🔒 | -| 2942 | [Find Words Containing Character](/solution/2900-2999/2942.Find%20Words%20Containing%20Character/README_EN.md) | | Easy | Biweekly Contest 118 | -| 2943 | [Maximize Area of Square Hole in Grid](/solution/2900-2999/2943.Maximize%20Area%20of%20Square%20Hole%20in%20Grid/README_EN.md) | | Medium | Biweekly Contest 118 | -| 2944 | [Minimum Number of Coins for Fruits](/solution/2900-2999/2944.Minimum%20Number%20of%20Coins%20for%20Fruits/README_EN.md) | | Medium | Biweekly Contest 118 | -| 2945 | [Find Maximum Non-decreasing Array Length](/solution/2900-2999/2945.Find%20Maximum%20Non-decreasing%20Array%20Length/README_EN.md) | | Hard | Biweekly Contest 118 | -| 2946 | [Matrix Similarity After Cyclic Shifts](/solution/2900-2999/2946.Matrix%20Similarity%20After%20Cyclic%20Shifts/README_EN.md) | | Easy | Weekly Contest 373 | -| 2947 | [Count Beautiful Substrings I](/solution/2900-2999/2947.Count%20Beautiful%20Substrings%20I/README_EN.md) | | Medium | Weekly Contest 373 | -| 2948 | [Make Lexicographically Smallest Array by Swapping Elements](/solution/2900-2999/2948.Make%20Lexicographically%20Smallest%20Array%20by%20Swapping%20Elements/README_EN.md) | | Medium | Weekly Contest 373 | -| 2949 | [Count Beautiful Substrings II](/solution/2900-2999/2949.Count%20Beautiful%20Substrings%20II/README_EN.md) | | Hard | Weekly Contest 373 | +| 2941 | [Maximum GCD-Sum of a Subarray](/solution/2900-2999/2941.Maximum%20GCD-Sum%20of%20a%20Subarray/README_EN.md) | `Array`,`Math`,`Binary Search`,`Number Theory` | Hard | 🔒 | +| 2942 | [Find Words Containing Character](/solution/2900-2999/2942.Find%20Words%20Containing%20Character/README_EN.md) | `Array`,`String` | Easy | Biweekly Contest 118 | +| 2943 | [Maximize Area of Square Hole in Grid](/solution/2900-2999/2943.Maximize%20Area%20of%20Square%20Hole%20in%20Grid/README_EN.md) | `Array`,`Sorting` | Medium | Biweekly Contest 118 | +| 2944 | [Minimum Number of Coins for Fruits](/solution/2900-2999/2944.Minimum%20Number%20of%20Coins%20for%20Fruits/README_EN.md) | `Queue`,`Array`,`Dynamic Programming`,`Monotonic Queue` | Medium | Biweekly Contest 118 | +| 2945 | [Find Maximum Non-decreasing Array Length](/solution/2900-2999/2945.Find%20Maximum%20Non-decreasing%20Array%20Length/README_EN.md) | `Stack`,`Queue`,`Array`,`Binary Search`,`Dynamic Programming`,`Monotonic Queue`,`Monotonic Stack` | Hard | Biweekly Contest 118 | +| 2946 | [Matrix Similarity After Cyclic Shifts](/solution/2900-2999/2946.Matrix%20Similarity%20After%20Cyclic%20Shifts/README_EN.md) | `Array`,`Math`,`Matrix`,`Simulation` | Easy | Weekly Contest 373 | +| 2947 | [Count Beautiful Substrings I](/solution/2900-2999/2947.Count%20Beautiful%20Substrings%20I/README_EN.md) | `String`,`Enumeration`,`Prefix Sum` | Medium | Weekly Contest 373 | +| 2948 | [Make Lexicographically Smallest Array by Swapping Elements](/solution/2900-2999/2948.Make%20Lexicographically%20Smallest%20Array%20by%20Swapping%20Elements/README_EN.md) | `Union Find`,`Array`,`Sorting` | Medium | Weekly Contest 373 | +| 2949 | [Count Beautiful Substrings II](/solution/2900-2999/2949.Count%20Beautiful%20Substrings%20II/README_EN.md) | `Hash Table`,`Math`,`String`,`Number Theory`,`Prefix Sum` | Hard | Weekly Contest 373 | | 2950 | [Number of Divisible Substrings](/solution/2900-2999/2950.Number%20of%20Divisible%20Substrings/README_EN.md) | | Medium | 🔒 | ## Copyright diff --git a/solution/summary.md b/solution/summary.md index 59807bee58221..5d6d5803a68de 100644 --- a/solution/summary.md +++ b/solution/summary.md @@ -2577,7 +2577,7 @@ - [2525.根据规则将箱子分类](/solution/2500-2599/2525.Categorize%20Box%20According%20to%20Criteria/README.md) - [2526.找到数据流中的连续整数](/solution/2500-2599/2526.Find%20Consecutive%20Integers%20from%20a%20Data%20Stream/README.md) - [2527.查询数组 Xor 美丽值](/solution/2500-2599/2527.Find%20Xor-Beauty%20of%20Array/README.md) - - [2528.最大化城市的最小供电站数目](/solution/2500-2599/2528.Maximize%20the%20Minimum%20Powered%20City/README.md) + - [2528.最大化城市的最小电量](/solution/2500-2599/2528.Maximize%20the%20Minimum%20Powered%20City/README.md) - [2529.正整数和负整数的最大计数](/solution/2500-2599/2529.Maximum%20Count%20of%20Positive%20Integer%20and%20Negative%20Integer/README.md) - [2530.执行 K 次操作后的最大分数](/solution/2500-2599/2530.Maximal%20Score%20After%20Applying%20K%20Operations/README.md) - [2531.使字符串总不同字符的数目相等](/solution/2500-2599/2531.Make%20Number%20of%20Distinct%20Characters%20Equal/README.md) @@ -2998,7 +2998,7 @@ - [2938.区分黑球与白球](/solution/2900-2999/2938.Separate%20Black%20and%20White%20Balls/README.md) - [2939.最大异或乘积](/solution/2900-2999/2939.Maximum%20Xor%20Product/README.md) - [2940.找到 Alice 和 Bob 可以相遇的建筑](/solution/2900-2999/2940.Find%20Building%20Where%20Alice%20and%20Bob%20Can%20Meet/README.md) - - [2941.Maximum GCD-Sum of a Subarray](/solution/2900-2999/2941.Maximum%20GCD-Sum%20of%20a%20Subarray/README.md) + - [2941.子数组的最大 GCD-Sum](/solution/2900-2999/2941.Maximum%20GCD-Sum%20of%20a%20Subarray/README.md) - [2942.查找包含给定字符的单词](/solution/2900-2999/2942.Find%20Words%20Containing%20Character/README.md) - [2943.最大化网格图中正方形空洞的面积](/solution/2900-2999/2943.Maximize%20Area%20of%20Square%20Hole%20in%20Grid/README.md) - [2944.购买水果需要的最少金币数](/solution/2900-2999/2944.Minimum%20Number%20of%20Coins%20for%20Fruits/README.md) @@ -3007,4 +3007,4 @@ - [2947.统计美丽子字符串 I](/solution/2900-2999/2947.Count%20Beautiful%20Substrings%20I/README.md) - [2948.交换得到字典序最小的数组](/solution/2900-2999/2948.Make%20Lexicographically%20Smallest%20Array%20by%20Swapping%20Elements/README.md) - [2949.统计美丽子字符串 II](/solution/2900-2999/2949.Count%20Beautiful%20Substrings%20II/README.md) - - [2950.Number of Divisible Substrings](/solution/2900-2999/2950.Number%20of%20Divisible%20Substrings/README.md) + - [2950.可整除子串的数量](/solution/2900-2999/2950.Number%20of%20Divisible%20Substrings/README.md)