
For a detailed overview of RAG evaluation package refer to the Medium Blog.
The Eval_Package is a tool designed to evaluate the performance of the LLM (Language Model) on a dataset containing questions, context, and ideal answers. It allows you to run evaluations on various datasets and assess how well the Model generates the answer.
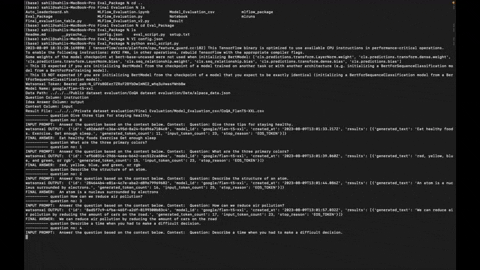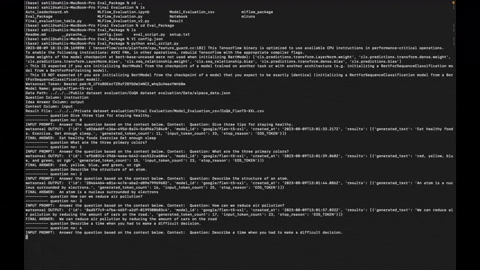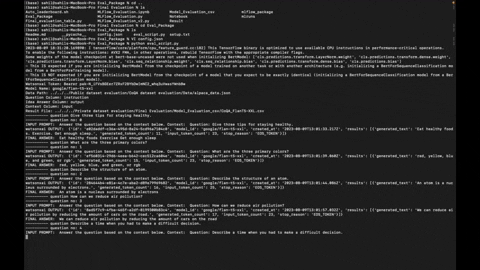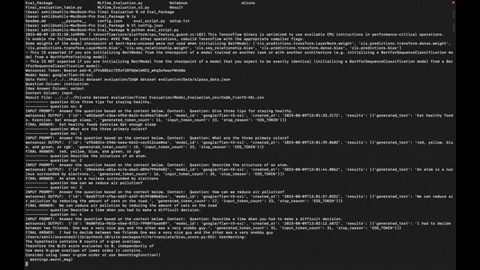
- Evaluate LLM Model on custom datasets: Use the Eval_Package to assess the performance of your Model on datasets of your choice.
- Measure model accuracy: The package provides metrics to gauge the accuracy of the model-generated answers against the ideal answers.
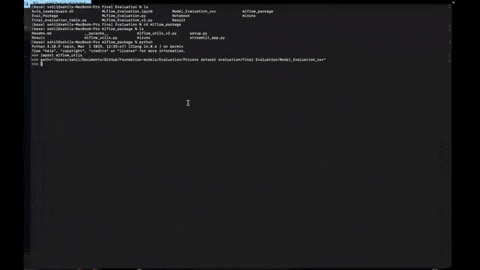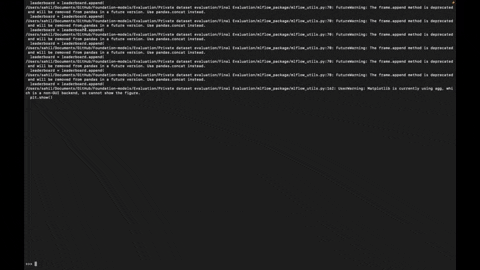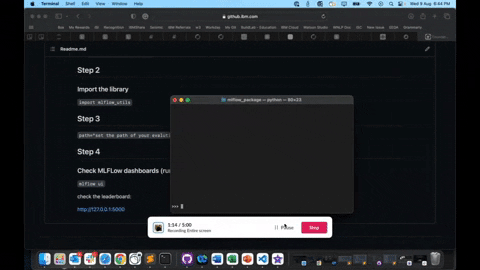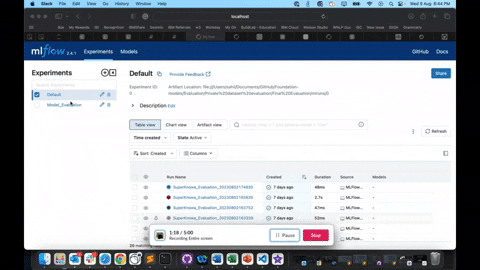
The MLflow_Package is a comprehensive toolkit designed to integrate the results from the Eval_Package and efficiently track and manage experiments. It also enables you to create a leaderboard for evaluation comparisons and visualize metrics through a dashboard.
- Experiment tracking: Use MLflow to keep a record of experiments, including parameters, metrics, and model artifacts generated during evaluations.
- Leaderboard creation: The package allows you to create a leaderboard, making it easy to compare the performance of different Models across multiple datasets.
- Metric visualization: Generate insightful charts and graphs through the dashboard, allowing you to visualize and analyze evaluation metrics easily.

-
I. LLM Eval Toolkit: Toolkit for evaluating RAG pipeline
- Eval_Package: A package to automatically evaluate the LLM based RAG pipeline
- mlflow_package: A package to automatically add the evaluation results to the
-
II. MLFLOW Integration: MLFlOW evaluation dashboard scripts
- Notebook: Evaluation Notebook
- Output_CSV: Output CSV for LLM Models Evaluation
- Result: Result file and png of MLFLOW
- mlruns: MLFLOW metadata