注:当前项目为 Serverless Devs 应用,由于应用中会存在需要初始化才可运行的变量(例如应用部署地区、函数名等等),所以不推荐直接 Clone 本仓库到本地进行部署或直接复制 s.yaml 使用,强烈推荐通过
s init ${模版名称}的方法或应用中心进行初始化,详情可参考部署 & 体验 。
儿童有声读物的智能化自动化合生成,使用通义千问大模型+ Cosyvoice声音合成 + Flux 图像生成 + Paraformer 声音识别合成可用于生产的儿童有声读物
使用该项目,您需要有开通以下服务并拥有对应权限:
| 服务/业务 | 权限 | 相关文档 |
|---|---|---|
| 函数计算 | AliyunFCFullAccess | 帮助文档 计费文档 |
| 云工作流 | AliyunFnFFullAccess | 帮助文档 计费文档 |
| 对象存储 | AliyunFCServerlessDevsRolePolicy | 帮助文档 计费文档 |
| 专有网络 | AliyunFCServerlessDevsRolePolicy | 帮助文档 计费文档 |
- 🔥 通过 Serverless 应用中心 ,
该应用。

- 通过 Serverless Devs Cli 进行部署:
- 安装 Serverless Devs Cli 开发者工具 ,并进行授权信息配置 ;
- 初始化项目:
s init ai-audiobook-flow -d ai-audiobook-flow - 进入项目,并进行项目部署:
cd ai-audiobook-flow && s deploy -y

有声读物广泛应用于 教育,影视,文化等行业。您可以为自己的孩子构建儿童读物,也可以将有价值的文案转换成视频,只需要输入自己 的内容,然后进行声音和语言的选项就可以完成制作,超级简单!
该项目交互操作简单,架构结构清晰,适用于普通用户,专业开发者,以及企业业务相关都可以尝试利用该项目满足自身诉求。
-
普通用户如自媒体创作者,宝妈等。只需要根据操作,完成一键部署,然后打开web前端页面就可以使用该服务合成您想要的任意视频读物
-
开发者可以基于相关的源码或者API定制自身的软件产品
-
企业可以参考基于阿里云AI基础实施 + Serverless 工作流构建的完整方案, 该方案借助于阿里云的全套AI能力以及Serverless的灵活架构在视频合成领域可以实现有利的竞争优势,如拟人化的声音,高清图片, 字幕添加等素材的合成,以及Serverless分片视频渲染带来的视频合成效率的提升
内容输出后,经过工作流程完成素材生成,最后进行视频的合成
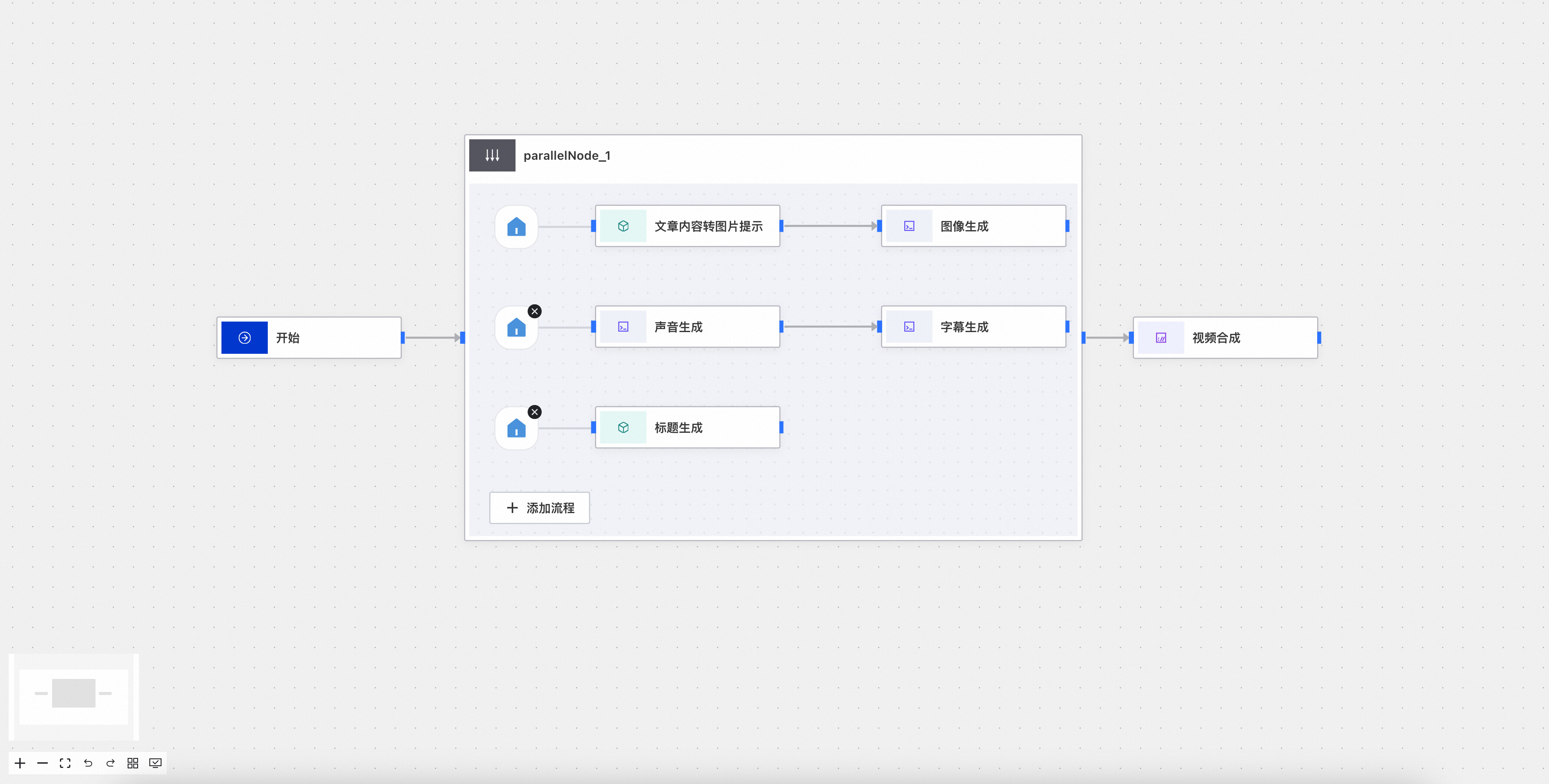
步骤一:部署好之后按照下图的指示打开web界面

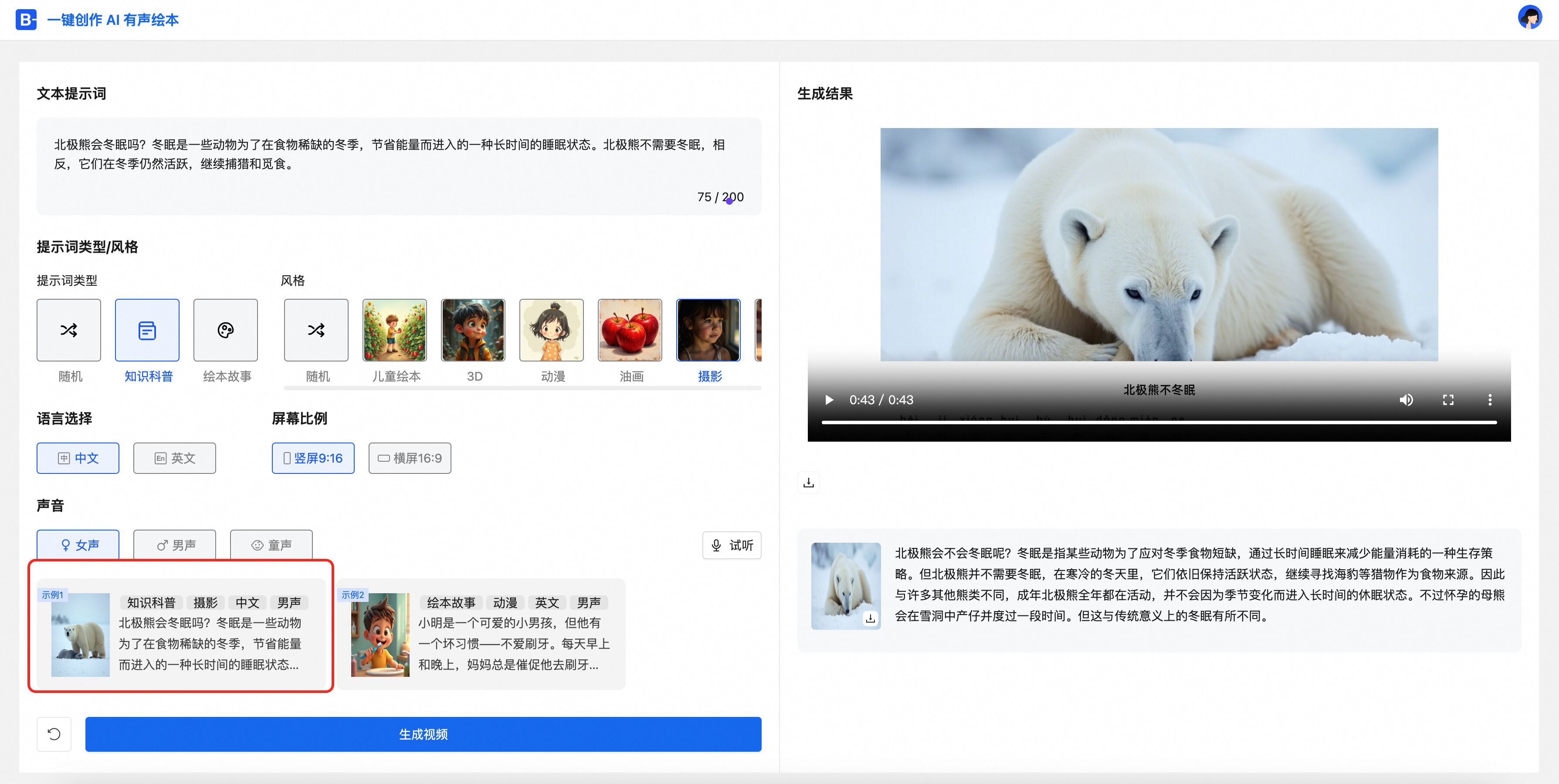
步骤二:选择示例模版,您同时也可以自由组合属性,如提示词类型,画面风格,语言,屏幕比例,声音等
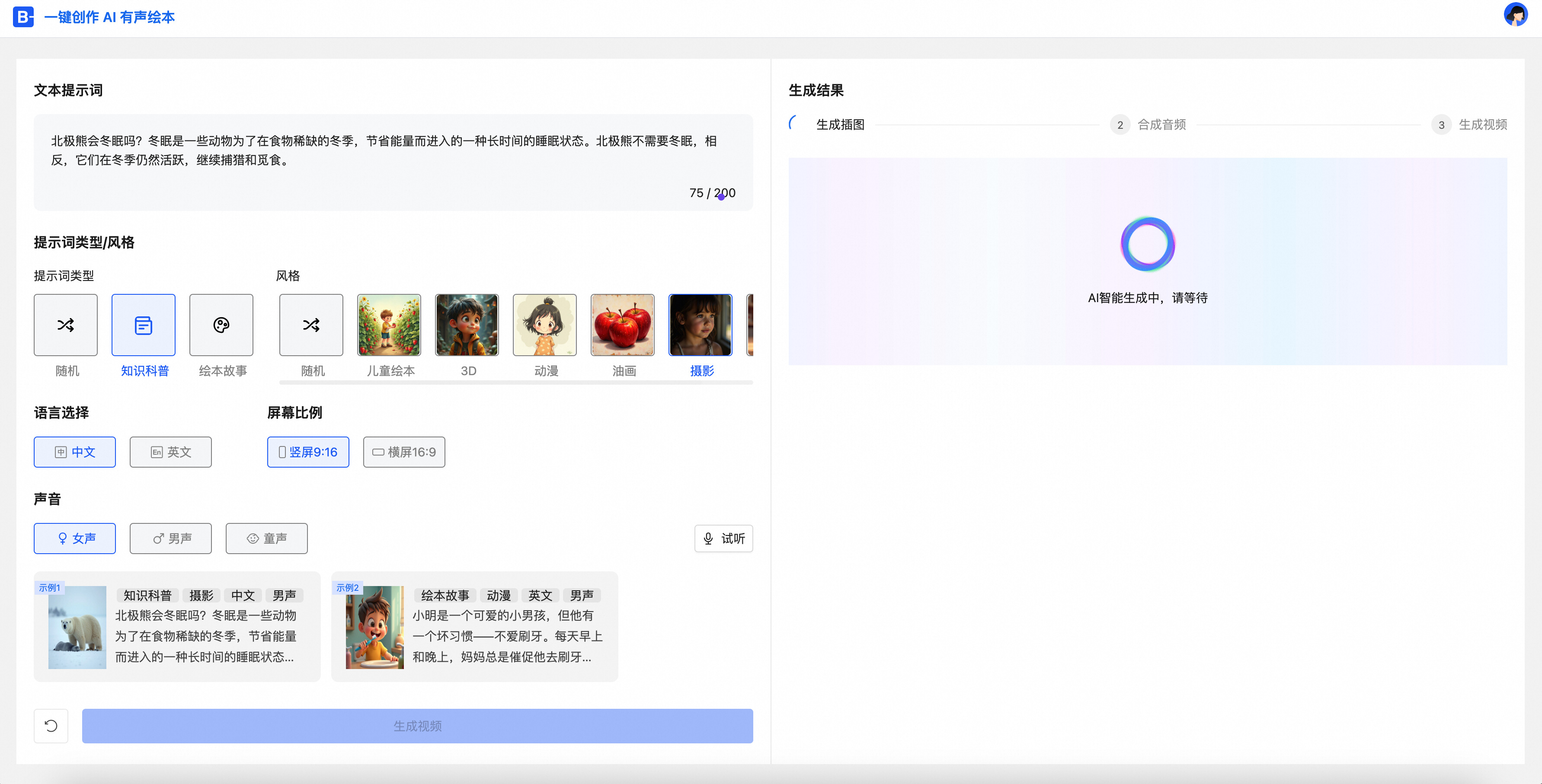
步骤三:等待渲染结果(约2-5分钟根据内容时间有所差异)
等待渲染结果,您可以访问任务执行地址,您也可以登录CloudFlow 工作流的名称为ai-audiobook-flow-xxx查看工作流的详细执行过程

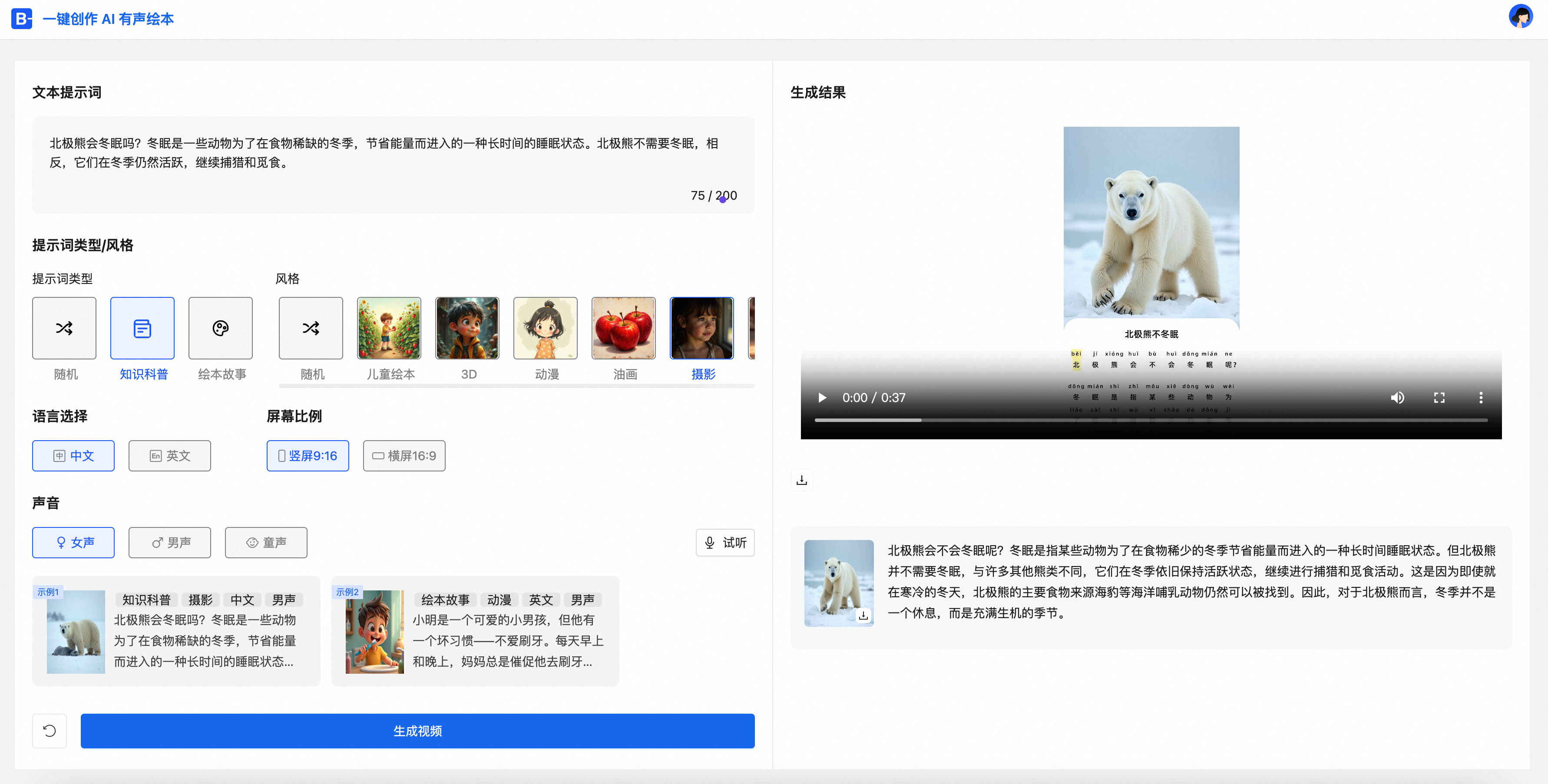
渲染结果如下:
您如果有关于错误的反馈或者未来的期待,您可以在 Serverless Devs repo Issues 中进行反馈和交流。如果您想要加入我们的讨论组或者了解 FC 组件的最新动态,您可以通过以下渠道进行:
 |
 |
 |
|---|---|---|
微信公众号:serverless |
微信小助手:xiaojiangwh |
钉钉交流群:33947367 |