So what are we trying to build?
- We want to design a system that can automatically store and handle the logs from multiple services.
Mechanism Mechanism Mechanism
A B C
| | |
> Service 1 -------- Zookeeper | |
\ & | |
> Service 2 ---------> Kafka --------> ClickHouse -------> Superset
/(Rsyslog)
> Service n --------
Notes:
- Each service represents a Docker Container.
- Zookeeper is a MUST for Kafka. Why?
- To save space, we can try to run Zookeeper, Kafka, ClickHouse, Superset in a single container.
Let's have a brief introduction about some of the framework we might be using, and why they could possibly help.
- Kafka:
- Kafka is an open source software which provides a framework for storing, reading and analysing streaming data. Simply speaking, Kafka works like a messaging queue, but distributedly.
- We can use Kafka to distribute log messages from multiple services. 3 Kafka main components: producers, consumers, brokers (nodes). Kafka messages are distributed under a "topic". Read more on Kafka website.
- Multiple Kafka nodes should be used in deployment, and Zookeeper is mandatory to help manage Kafka nodes. Read more about Zookeeper here: https://zookeeper.apache.org/
- ClickHouse
- ClickHouse is a fast open-source OLAP database management system.
- We can benefit from ClickHouse Kafka Engine (which helps to connect with Kafka) and ClickHouse connection with Superset.
- Superset
- Able to connect to ClickHouse and visualize data.
1. Mechanism A: Transmits all logging messages from multiple services (Docker Containers) to Kafka.
- First, we need to figure out how Docker handle its logging -> Docker Logging Driver.
- I propose 3 possible solutions:
- Moby Kafka Logdriver: A Docker plugin that works as a logdriver, transmit all log messages to Kafka.
- Rsyslog: Transmit all log messages to a rsyslog server, then rsyslog decides where the messages go. Rsyslog Project For Kafka
- Other ways than Moby to configure a custom logging mechanism for all services, and then some way to produce log messages to Kafka.
2. Mechanism B: Configure ClickHouse to automatically receive data from Kafka.
Check out this really helpful tutorial: Link
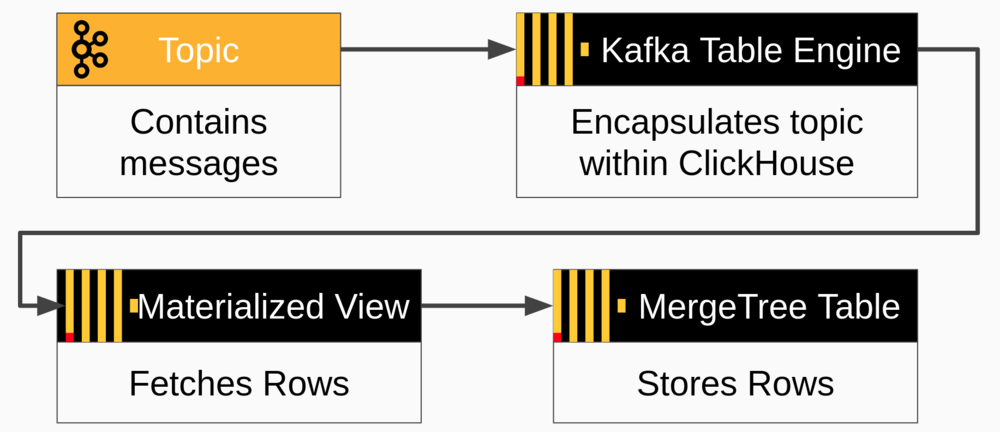
- Note: We can configure each table to receive messages from Kafka topics (They are basically Kafka consumers).
3. Mechanism C: Configure Superset to visualize ClickHouse data
- Setup Superset User Interface. Use the interface to connect to ClickHouse URI -> Then it's all done!
We will test exploration with a full demo that handles the logs of 3 seperate services.
Note: You will need to edit the IP address in this file and inside docker-compose.yml to match you machine's.
Let's follow the design below
Kafka Kafka
Log Driver Table Engine
| |
> Service 1 -------- Zookeeper |
\ & |
> Service 2 ---------> Kafka --------> ClickHouse -------> Superset
/(Rsyslog)
> Service n --------
Start the demo by running our base services
- Run Kafka & Zookeeper, ClickHouse, Superset: Remember to edit docker-compose.yml to fit your machine settings.
$ sudo docker-compose up -d- Init a variable as your machine IP address:
$ IP_ADDRESS={YOUR_MACHINE_IP_ADDRESS}- Create 3 topics:
$ sudo docker exec -it kafka-broker kafka-topics \
--zookeeper $IP_ADDRESS:2181 \
--create \
--topic service_1 \
--partitions 6 \
--replication-factor 1$ sudo docker exec -it kafka-broker kafka-topics \
--zookeeper $IP_ADDRESS:2181 \
--create \
--topic service_2 \
--partitions 6 \
--replication-factor 1$ sudo docker exec -it kafka-broker kafka-topics \
--zookeeper $IP_ADDRESS:2181 \
--create \
--topic service_3 \
--partitions 6 \
--replication-factor 1- Check if the topic is created or not:
$ sudo docker exec -it kafka-broker kafka-topics \
--zookeeper $IP_ADDRESS:2181 \
--describe1. Start 3 services that always generate logs and send to Kafka using Kafka Log Driver
First, we need to install and configure Kafka Log Driver, we will need 3 seperate plugins for 3 services.
- Set a local name for each plugin.
- Disable to configure them first before running.
- More detailed guide: https://github.com/MickayG/moby-kafka-logdriver
$ sudo docker plugin install --alias service_1_logdriver --disable mickyg/kafka-logdriver:latest
$ sudo docker plugin set service_1_logdriver KAFKA_BROKER_ADDR="192.168.1.40:9091"
$ sudo docker plugin set service_1_logdriver LOG_TOPIC=service_1
$ sudo docker plugin enable service_1_logdriver:latest$ sudo docker plugin install --alias service_2_logdriver --disable mickyg/kafka-logdriver:latest
$ sudo docker plugin set service_2_logdriver KAFKA_BROKER_ADDR="192.168.1.40:9091"
$ sudo docker plugin set service_2_logdriver LOG_TOPIC=service_2
$ sudo docker plugin enable service_2_logdriver$ sudo docker plugin install --alias service_3_logdriver --disable mickyg/kafka-logdriver:latest
$ sudo docker plugin set service_3_logdriver KAFKA_BROKER_ADDR="192.168.1.40:9091"
$ sudo docker plugin set service_3_logdriver LOG_TOPIC=service_3
$ sudo docker plugin enable service_3_logdriverBuild our random logger images:
$ sudo docker build -t random-logger_1 ./random-logger
$ sudo docker build -t random-logger_2 ./random-logger
$ sudo docker build -t random-logger_3 ./random-loggerRun 3 services with configured log drivers:
$ sudo docker run --detach --log-driver service_1_logdriver random-logger_1
$ sudo docker run --detach --log-driver service_2_logdriver random-logger_2
$ sudo docker run --detach --log-driver service_3_logdriver random-logger_3Make sure that Kafka is receiving the log messages by creating a consumer that is subscribed to each topic. The message should be appearing on the command line window. Later on, ClickHouse will be our Kafka Consumer.
$ sudo docker exec -it kafka-broker kafka-console-consumer --bootstrap-server 192.168.1.40:9091 --topic service_12. Configure ClickHouse as a Kafka Consumer
-
Configure ClickHouse to receive data from Kafka
-
Let's design the ClickHouse data tables based on our logging messages, which is a one row nested JSON format. I will work with the first layer of JSON only, the nested part need to be handled later on.
{"Line":"{"@timestamp": "2021-07-08T10:44:08+0000", "level": "WARN", "message": "variable not in use."}","Source":"stdout","Timestamp":"2021-07-08T10:44:08.349998689Z","Partial":false,"ContainerName":"/cool_shamir","ContainerId":"4e07abaf3345e8d8b026826c49d3193e401e2635781dae86cbd57ec9579d18c1","ContainerImageName":"random-logger","ContainerImageId":"sha256:cbc554adcaabd8ce581d438a2223d2ebae3ccb84d477867b63bdfb4b91632067","Err":null}
- Let's split this up for a better look:
{
"Line":"{"@timestamp": "2021-07-08T10:44:08+0000", "level": "WARN", "message": "variable not in use."}",
"Source":"stdout",
"Timestamp":"2021-07-08T10:44:08.349998689Z",
"Partial":false,
"ContainerName":"/cool_shamir",
"ContainerId":"4e07abaf3345e8d8b026826c49d3193e401e2635781dae86cbd57ec9579d18c1",
"ContainerImageName":"random-logger",
"ContainerImageId":"sha256:cbc554adcaabd8ce581d438a2223d2ebae3ccb84d477867b63bdfb4b91632067",
"Err":null
}- Open ClickHouse CLI
$ sudo docker exec -it clickhouse bin/bash -c "clickhouse-client --multiline"Important: Repeat this design for each service, below is a demo for service_1 JSONEachRow
# Create a MergeTree Table
CREATE TABLE service_1 (
time DateTime Codec(DoubleDelta, LZ4),
Line String,
level String,
message String,
Source String,
Timestamp String,
Partial String,
ContainerName String,
ContainerImageName String,
ContainerImageId String,
Err String
) Engine = MergeTree
PARTITION BY toYYYYMM(time)
ORDER BY (time);# Create Kafka Table Engine
CREATE TABLE service_1_queue (
Line String,
level String,
message String,
Source String,
Timestamp String,
Partial String,
ContainerName String,
ContainerImageName String,
ContainerImageId String,
Err String
)
ENGINE = Kafka
SETTINGS kafka_broker_list = '192.168.1.40:9091',
kafka_topic_list = 'service_1',
kafka_group_name = 'service_1_consumer_1',
kafka_format = 'CSV',
kafka_max_block_size = 1048576;# Create a materialized view to transfer data
# between Kafka and the merge tree table
CREATE MATERIALIZED VIEW service_1_queue_mv TO service_1 AS
SELECT Line, level, message, Source, Timestamp, Partial, ContainerName, ContainerImageName, ContainerImageId, Err
FROM service_1_queue;-
(Optional because the services has been producing messages already) Test the setup by producing some messages
sudo docker exec -it kafka-broker kafka-console-producer \ --broker-list 192.168.1.40:9091 \ --topic readings -
Use this data
{"Line":"{\"@timestamp\": \"2021-07-08T10:44:08+0000\", \"level\": \"WARN\", \"message\": \"variable not in use.\"}","Source":"stdout","Timestamp":"2021-07-08T10:44:08.349998689Z","Partial":false,"ContainerName":"/cool_shamir","ContainerId":"4e07abaf3345e8d8b026826c49d3193e401e2635781dae86cbd57ec9579d18c1","ContainerImageName":"random-logger","ContainerImageId":"sha256:cbc554adcaabd8ce581d438a2223d2ebae3ccb84d477867b63bdfb4b91632067","Err":null}
3. Configure SuperSet to get data from ClickHouse
-
Register a root SuperSet account
$ sudo docker exec -it superset superset-init -
Connect to ClickHouse
- Use the UI at localhost:8080
- Add Clickhouse URI to Superset: clickhouse://clickhouse:8123
- Then you should be able to visualize some ClickHouse Tables
To summarize, 3 things that I was not able to do yet includes:
- Making ClickHouse handle JSON messages from Kafka (JSON mapping)
- Merging all logging services into 1 logging container, so the demo is still using 4 containers: Kafka, Zookeeper, ClickHouse, Superset.
- Fix the Superset - ClickHouse bug: Superset can connect to ClickHouse just fine, can recognize the table, but data on the table is always empty? Although the table is actually NOT empty.