
Picky facilitates efficient, reproducible and selective sharing of large scientific datasets.
- Java 9
- checkout sources
- run
./gradlew shadowJarin project root
The build is going to produce two artefacts of interest:
- picky-indexer/build/libs/picky-indexer-0.4-jar
- picky-client/build/libs/picky-client-0.4.jar
Run them using a Java 9 SDK like java -jar picky-client/build/libs/picky-client-0.4.jar
Hint: Picky is quite memory heavy for large datasets. Make sure to assign enough memory to Java in case you experience hangs, crashes or OutOfMemoryExceptions. Run Java with the parameter -Xmx15G to start it with a maxium of 15GB heap memory - adjust the size to your needs.
Picky consist of two parts, an indexer for server-side preparation and a download client.
To share a dataset using Picky, you need to perform the following steps:
Picky works on a directory as an entry point to your dataset. The directory may contain subdirectories and files. After downloading, Picky will reconstruct the source directory on the users machine, maintaining directory layout, file names and last modified timestamps.
To index the dataset, run java -jar picky-indexer-0.2-SNAPSHOT-jar-with-dependencies.jar with the following parameters:
| Parameter | Req. | Description |
|---|---|---|
-s (--source) |
yes | Source directory to create index from (e.g. '/local/dataset') |
-t (--target) |
yes | Target directory to create index in (e.g. '/local/index') |
-r (--reference) |
yes | Unique userfriendly reference name |
-m (--tmp) |
yes | Tmp directory (e.g. '/tmp') |
-p (--parser) |
yes | Full-quallified class name of IEntryParser implementation |
-n (--description) |
no | Short dataset description |
-i (--icon) |
no | Dataset or provider icon file (e.g. '/local/icon.png') |
-u (--url) |
no | Website URL, e.g. further information related to the dataset |
-l (--logLevel) |
no | Log Level (Default: INFO) |
-c (--chunkSizeLimit) |
no | Chunk size limit in byte (Default: 5MB) |
Depending on the size of the dataset and the available computational resources, indexing will take quite some time, as the entire dataset will be read, parsed, compressed, hashed and stored.
- CPU Indexing is usually CPU-bound and Picky makes use of all available cores, so increasing the number of cores will speed up indexing.
- Memory Picky tries to work with reasonable memory consumption. The minimum requirement depends solely on the nature of the dataset and the configuration. Since it Java, however, keep in mind that more memory reduces the need for garbage collection and thus speeds up indexing.
- Storage The target directory will need to have sufficient storage space to store the compressed (gzip) dataset. Indexing adds some additional information to the dataset, so expect the resulting index to be somewhat larger compared to compressing the bare dataset.
Indexing can take several days. You can kill the process at any time and restart it later. Should the process crash (e.g. for running out of memory), you can also start it again and it will continue its work. Should you required a clean start, delete the temp directory where interim result are cached.
The index created by the previous step is literally a directory structure containing a lot of files used by the Picky download client. The index can be made available to others by a number of common file transfer techniques, including direct file access, sftp, and http.
A common way of publishing would hence be setting up an arbitrary webserver (e.g. nginx) to server the index directory. To access the dataset, clients will need to know the URL of the server as well as the reference name specified during indexing.
Updating the dataset is easy - simply repeat the indexing process, using the already existing index as target. Updating can be performed without interfering with clients downloading an already published version from the same index. If the same reference name is used, subsequent downloads will the point to the new version. You can, however, choose to incorporate some versioning scheme for the reference name, to allow access to prior versions of the dataset. Note that indexing will only add changed data to the index, so updates are fairly resource efficient both in terms of server storage and bandwidth.
On begin and end of the download process, Picky tries to report usage statistics to the dataset publisher to allow for a better understanding of which parts of the dataset are relevant for clients. It will do so by posting a UTF-8 plain text file to the server URL + /analytics. The information collected are in detail:
- dataset Id
- dataset description
- number of chunks in dataset
- number of files in dataset
- average number of blocks in dataset
- file filter
- number of matching files
- selected entries
- number of files and directories to create, update or delete
- number of chunks to download
- remaining bytes to download
- bytes downloaded
Note that no other information - especially no private information regarding the user's system or files - are transmitted. See Analytics.java for details.
To download a dataset, run java -jar picky-client-0.2-SNAPSHOT.jar. The client can be used as follows:
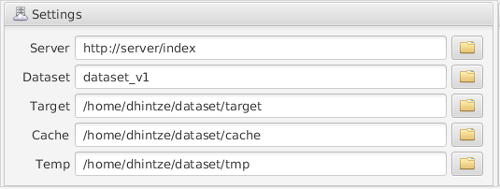
Configure the server providing the index, the reference name, the target directory, a cache directory and a temp directory. Note that the download client will alter the target directory to synchronize it with the selected dataset subset. This includes changing and deleting any files present if necessary!
The cache directory stores compressed parts of the dataset and comes in handy if the dataset subset selection is changed later. It can, however, be safely deleted to reclaim some storage space if necessary.
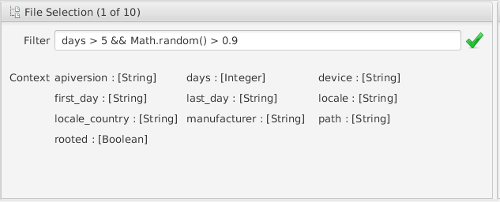
Subsets can be defined on file level by specifying a filter rule. The filter rule is a boolean JavaScript expression evaluated for each of the files present in the original dataset. Metadata privided during indexing are available for decision making, as well as file-independent functions such as Math.random().
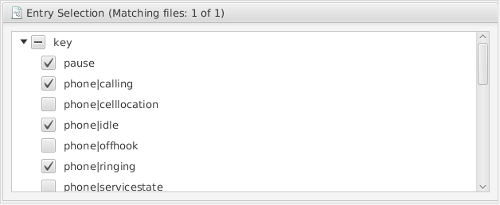
Subsets can also be defined on entry, i.e. subfile-level. Depending on the nature of the dataset, the user is presented a choice of key/value features available for entries within the dataset. The client will download and install only selected entries.
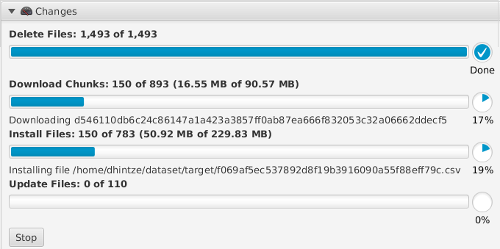
Any time settings or selections are changed, the client analyses the target directory and calculates all changes required in order to make it match the specified dataset subset. Push 'Apply Changes' to actually start downloading data and applying the calculated changes to the specified target directory.
- Fix some Indexer IO inefficiencies
- Fix UI update bug
- A number of small bugfixes and stability improvements
- Dependency updates
- Upgrade to Java 9
- Move build system from Maven to Gradle
- Upload usage statistics
- Enhanced progress feedback
- Start/stop option
- First version published
[1] D. Hintze and A. Rice: Picky: Efficient and Reproducible Sharing of Large Datasets Using Merkle-Trees, 2016 IEEE 24th International Symposium on Modeling, Analysis and Simulation of Computer and Telecommunication Systems (MASCOTS), London, United Kingdom, 2016, pp. 30-38.