This source isn't intended to be used in a product. Yes, the license is GLWTPL, you are
free to use it in whatever way you want. However, this is just a result form my
two-week hackathon, to searching for a realtime pedestrian detector that can be
run on embedded hardware. Please, don't expect more from that. Besides, I'm too
busy now to turn it to a serious product, there is limited comment inside source
code as well, sorry about that.
- ANSI C & OpenCL implementation.
- Aggregated 10-channel features.
- 6 orientations HOG.
- 3 channel for LUV.
- Gradient magnitude.
- Fast feature pyramids.
- 1 real scale per octave.
- 7 approximated scales per octave.
- Constant rejection soft cascade.
- Performance on INRIA dataset.
18.65%log-average miss rate.- 60 FPS (640x480, integrated Intel 620 GPU).
ACF, invented by Piotr Dollár is the best non-deep algorithm for pedestrian
detection in my opinion. The only algorithm which could be considered as realtime for
embedded device now. Which was used as the baseline detector for dozens of variant
also. Combining the power of various channel with a boosted classifier, this algorithm
out-performs other state of art algorithms, both speed and accuracy. In stead of using
the integral images as the precursor (ICF), ACF aggregates these feature into a single
pixel, that is cheap to be stored, and crazy fast to lookup.
Another key to achieves realtime performance is fast pyramid features, that
was invented by the same author of ACF as well. Based on natural image research, he
discovered that there are relative relation between feature in nearby scales, which
is mostly correct as long at the scale distance is less than half of an octave. Therefore,
we can compute the pyramid sparely, and using that to approximate remaining.
The original implementation runs on single CPU core, heavily optimized with SIMD. In our work, I'm using OpenCL for both feature computing and classification. ACF feature is very fast to compute on my laptop with integrated Intel GPU, ~100 FPS. However, this feature image is quite big that can't be downloaded to classify on the CPU in my system. Therefore, we need to move entire of the classification onto the GPU as well.
Now, I got another problem, the work load was not distributed quite well, so the overall performance is horrible. Usually, there are many highscored window around the object, which only be rejected very late, or even pass through, that cost so much for computing. Eventually these window will be accidentally distributed onto the same core. That means there is a big bottle neck, especially on Nvidia system, it seems they trade-off single core performance for number of core. So despite the overall computing power, my desktop GPU performs even slower.
Therefore, we split the classification into two phases, using 32 week classifier as efficient window proposal, that rejects most of the negative window very fast and correct. Next, we redistribute these proposals in the fine detection phase with full of 4096 classifier. Now we have better utilization and realtime performance. This also means ACF is very good as region proposal for deep learning, much better in both speed and accuracy in comparison with selective search.
This is the demonstration video.
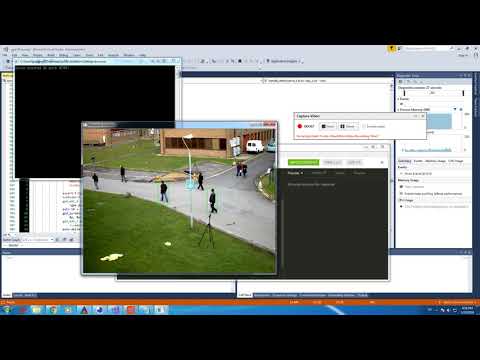
Well, if you want to run it on your machine, there is no convenient step by step guide here, sorry about that. Using CMake you can build it quite easily thought. It depends on python to generate the LUV table and OpenCL resource header. Servo is a reference application which depends on OpenCV for Video playing and visualization. However, core library isn't depends on that, it implemented purely with ANSI C and OpenCL. To control servo, using HTTP restful requests as described bellow.
Set the trained model:
URL: http://127.0.0.1:41991/classifier
METHOD: PUT
CONTENT-TYPE: application/octet-stream
BODY: << put your model here >>
Start demo:
URL: http://127.0.0.1:41991/demo
METHOD: POST
QUERY `stride`: 4
QUERY `casc_thr`: -1
QUERY `lambda_color`: 0.0023
QUERY `lambda_mag`: 0.1183
QUERY `lambda_hist`: 0.1312
There are other request which was intended for debug from MATLAB.
https://authors.library.caltech.edu/49239/7/DollarPAMI14pyramids_0.pdf